Probabilities of Single Step Events
This week your student will be working with probability. A probability is a number that represents how likely something is to happen. For example, think about flipping a coin.
- The probability that the coin lands somewhere is 1. That is certain.
- The probability that the coin lands heads up is $\frac12$, or 0.5.
- The probability that the coin turns into a bottle of ketchup is 0. That is impossible.
Sometimes we can figure out an exact probability. For example, if we pick a random date, the chance that it is on a weekend is $\frac{2}{7}$, because 2 out of every 7 days fall on the weekend. Other times, we can estimate a probability based on what we have observed in the past.
Here is a task to try with your student:
People at a fishing contest are writing down the type of each fish they catch. Here are their results:
- Person 1: bass, catfish, catfish, bass, bass, bass
- Person 2: catfish, catfish, bass, bass, bass, bass, catfish, catfish, bass, catfish
- Person 3: bass, bass, bass, catfish, bass, bass, catfish, bass, catfish
- Estimate the probability that the next fish that gets caught will be a bass.
- Another person in the competition caught 5 fish. Predict how many of these fish were bass.
- Before the competition, the lake was stocked with equal numbers of catfish and bass. Describe some possible reasons for why the results do not show a probability of $\frac12$ for catching a bass.
Solution:
- About $\frac{15}{25}$, or 0.6, because of the 25 fish that have been caught, 15 of them were bass.
- About 3 bass, because $\frac35 = 0.6$. It would also be reasonable if they caught 2 or 4 bass, out of their 5 fish.
- There are many possible answers. For example:
- Maybe the lures or bait they were using are more likely to catch bass.
- With results from only 25 total fish caught, we can expect the results to vary a little from the exact probability.
Probabilities of Multi-step Events
To find an exact probability, it is important to know what outcomes are possible. For example, to show all the possible outcomes for flipping a coin and rolling a number cube, we can draw this tree diagram:
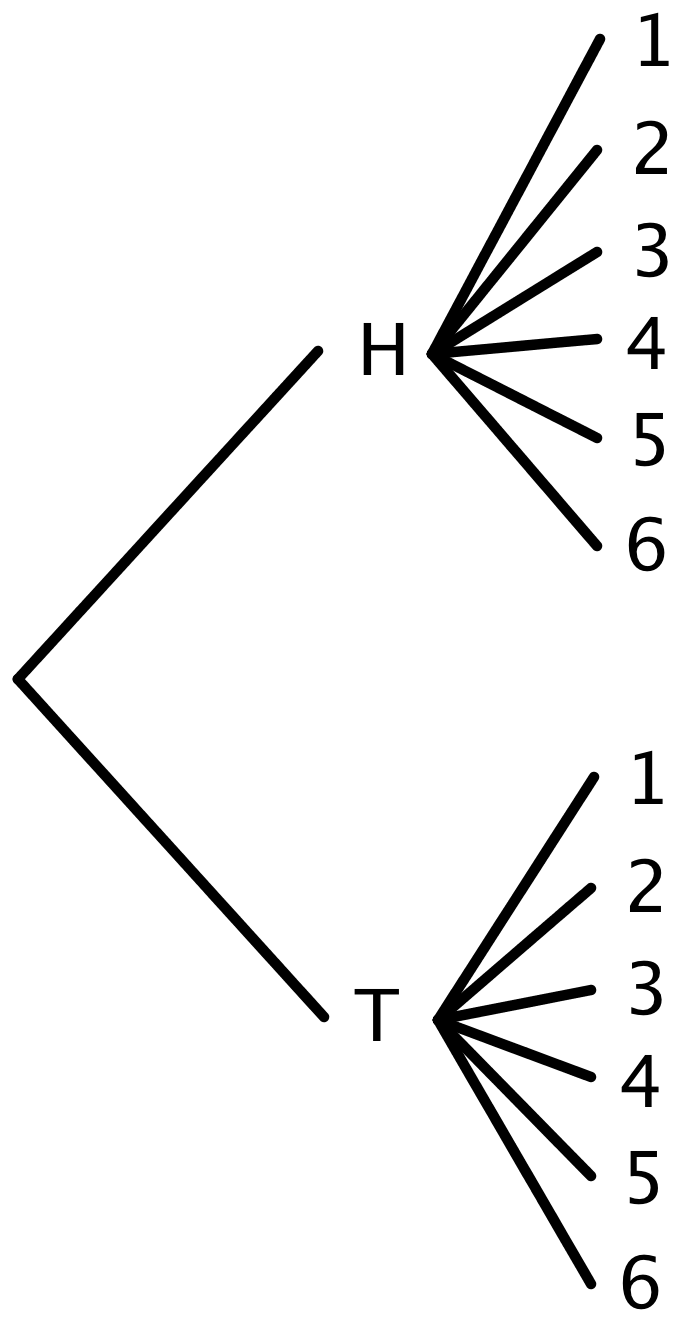
The branches on this tree diagram represent the 12 possible outcomes, from “heads 1” to “tails 6.” To find the probability of getting heads on the coin and an even number on the number cube, we can see that there are 3 ways this could happen (“heads 2”, “heads 4”, or “heads 6”) out of 12 possible outcomes. That means the probability is $\frac{3}{12}$, or 0.25.
Here is a task to try with your student:
A board game uses cards that say “forward” or “backward” and a spinner numbered from 1 to 5.
- On their turn, a person picks a card and spins the spinner to find out which way and how far to move their piece. How many different outcomes are possible?
- On their next turn, what is the probability that the person will:
- get to move their piece forward 5 spaces?
- have to move their piece backward some odd number of spaces?
Solution:
- There are 10 possible outcomes (“forward 1”, “forward 2”, “forward 3”, “forward 4”, “forward 5”, “backward 1”, “backward 2”, “backward 3”, “backward 4”, or “backward 5”).
-
- $\frac{1}{10}$ or 0.1, because “forward 5” is 1 out of the 10 possibilities.
- $\frac{3}{10}$ or 0.3, because there are 3 such possibilities (“backward 1”, “backward 3”, or “backward 5”)
Sampling
This week your student will be working with data. Sometimes we want to know information about a group, but the group is too large for us to be able to ask everyone. It can be useful to collect data from a sample (some of the group) of the population (the whole group). It is important for the sample to resemble the population.
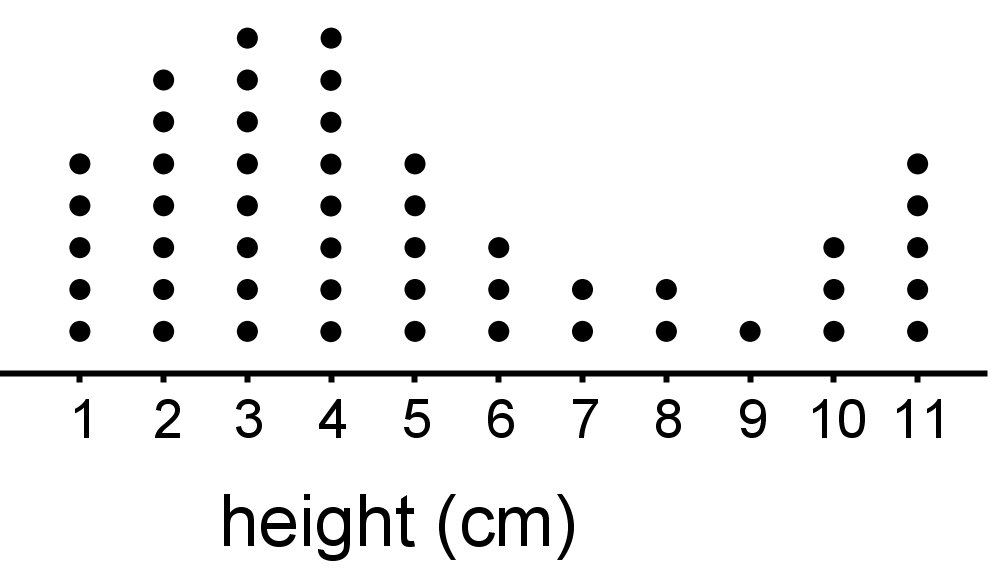
- For example, here is a dot plot showing a population: the height of 49 plants in a sprout garden.
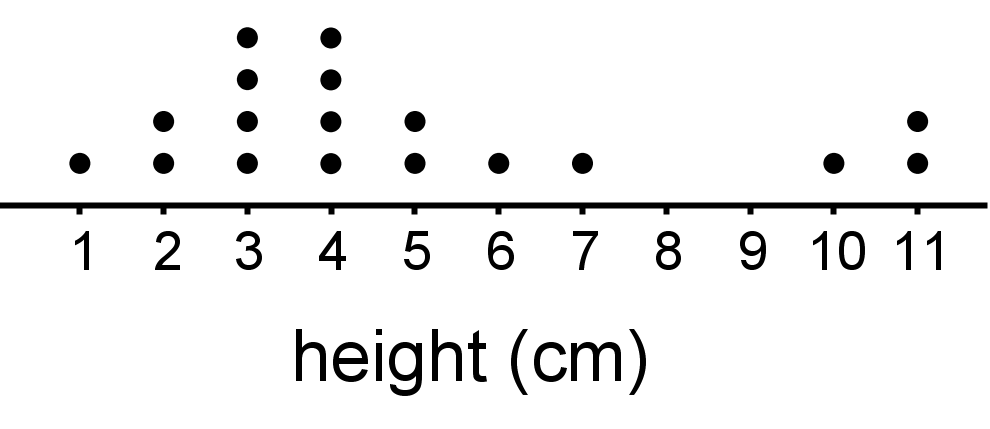
- This sample is representative of the population, because it includes only a part of the data, but it still resembles the population in shape, center, and spread.
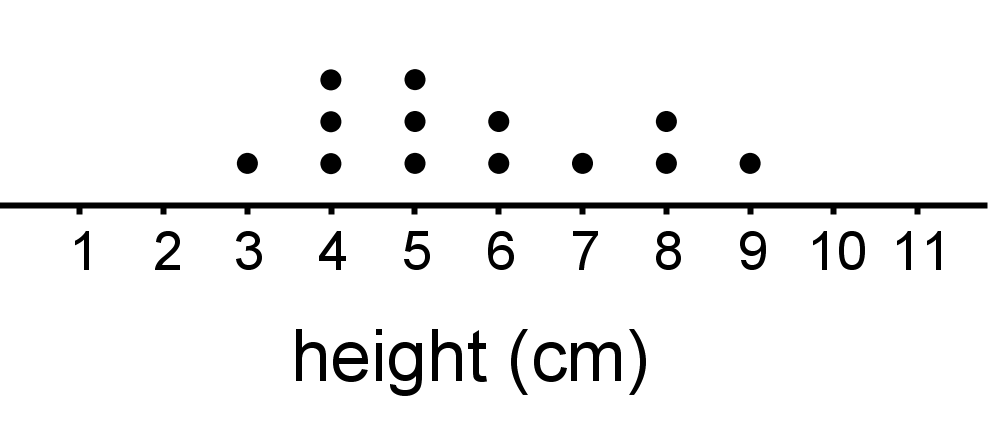
- This sample is not representative of the population. It has too many plant heights in the middle and not enough really short or really tall ones.
A sample that is selected at random is more likely to be representative of the population than a sample that was selected some other way.
Here is a task to try with your student:
A city council needs to know how many buildings in the city have lead paint, but they don’t have enough time to test all 100,000 buildings in the city. They want to test a sample of buildings that will be representative of the population.
- What would be a bad way to pick a sample of the buildings?
- What would be a good way to pick a sample of the buildings?
Solution:
- There are many possible answers.
- Testing all the same type of buildings (like all the schools, or all the gas stations) would not lead to a representative sample of all the buildings in the city.
- Testing buildings all in the same location, such as the buildings closest to city hall, would also be a bad way to get a sample.
- Testing all the newest buildings would bias the sample towards buildings that don’t have any lead paint.
- Testing a small number of buildings, like 5 or 10, would also make it harder to use the sample to make predictions about the entire population.
- To select a sample at random, they could put the addresses of all 100,000 buildings into a computer and have the computer select 50 addresses randomly from the list. Another possibility could be picking papers out a bag, but with so many buildings in the city, this method would be difficult.
Using Samples
We can use statistics from a sample (a part of the entire group) to estimate information about a population (the entire group). If the sample has more variability (is very spread out), we may not trust the estimate as much as we would if the numbers were closer together. For example, it would be easier to estimate the average height of all 3-year olds than all 40-year olds, because there is a wider range of adult heights.
We can also use samples to help predict whether there is a meaningful difference between two populations, or whether there is a lot of overlap in the data.
Here is a task to try with your student:
Students from seventh grade and ninth grade were selected at random to answer the question, “How many pencils do you have with you right now?” Here are the results:
how many pencils each seventh grade student had
| row 1 | 4 | 1 | 2 | 5 | 2 | 1 | 1 | 2 | 3 | 3 |
|---|
how many pencils each ninth grade student had
| row 1 | 9 | 4 | 1 | 14 | 6 | 2 | 0 | 8 | 2 | 5 |
|---|
- Use the sample data to estimate the mean (average) number of pencils carried by:
- all the seventh grade students in the whole school.
- all the ninth grade students in the whole school.
- Which sample had more variability? What does this tell you about your estimates in the previous question?
- A student, who was not in the survey, has 5 pencils with them. If this is all you know, can you predict which grade they are in?
Solution:
- Since the samples were selected at random, we predict they will represent the whole population fairly well.
- About 2.4 pencils for all seventh graders, because the mean of the sample is $(4+1+2+5+2+1+1+2+3+3) \div 10$ or 2.4 pencils.
- About 5.1 pencils for all ninth graders, because the mean of the sample is $(9+4+1+14+6+2+0+8+2+5) \div 10$ or 5.1 pencils.
- The survey of ninth graders had more variability. Those numbers were more spread out, so I trust my estimate for seventh grade more than I trust my estimate for ninth grade.
- There are many possible answers. For example:
- Since they only asked 10 students from each grade, it is hard to predict. It would help if they could ask more students.
- The student is probably in ninth grade, because 5 is closer to the sample mean from ninth grade than from seventh grade.
- The student could possibly be in seventh grade, because at least one student in seventh grade has 5 pencils.