We often collect and analyze data because we are interested in learning what is “typical,” or what is common and can be expected in a group.
Sometimes it is easy to tell what a typical member of the group is. For example, we can say that a typical shape in this set is a large circle.

Just looking at the members of a group doesn’t always tell us what is typical, however. For example, if we are interested in the side length typical of squares in this set, it isn’t easy to do so just by studying the set visually.

In a situation like this, it is helpful to gather the side lengths of the squares in the set and look at their distribution, as shown in this dot plot.
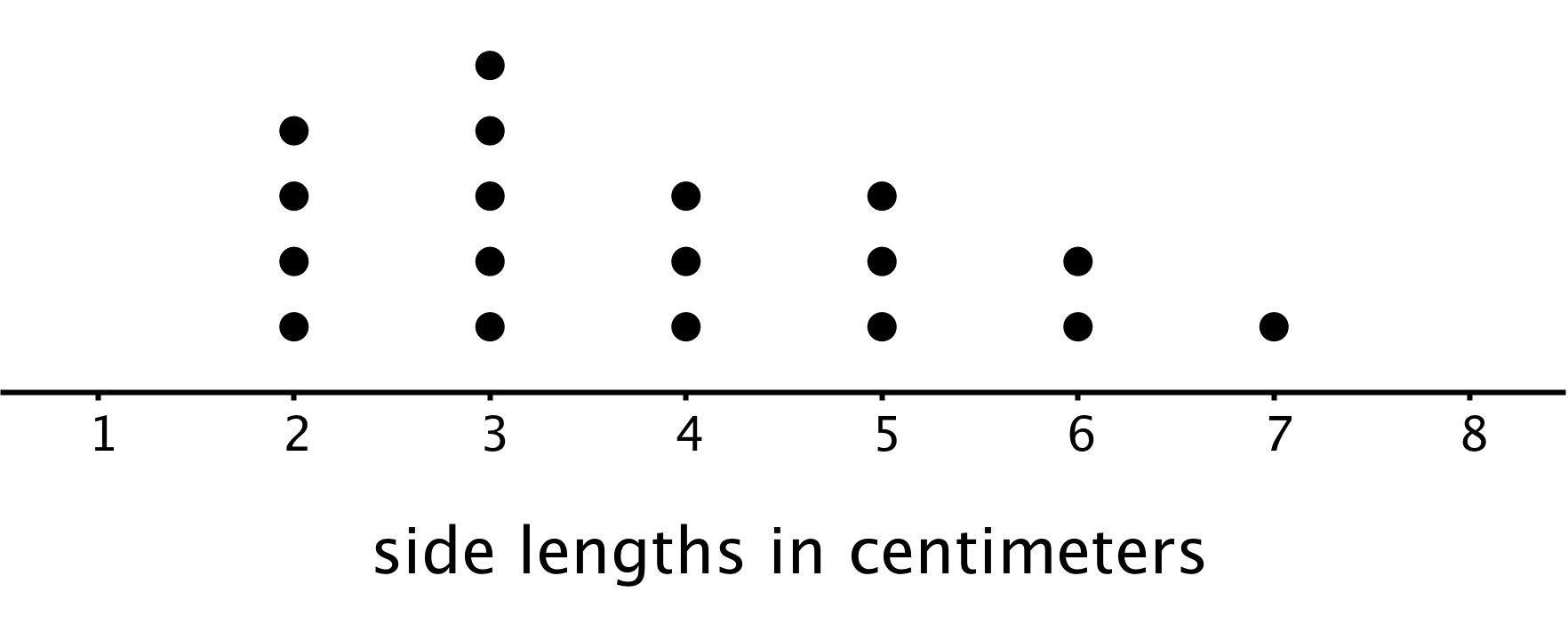
We can see that many of the data points are between 2 and 4, so we could say that side lengths between 2 and 4 centimeters or close to these lengths are typical of squares in this set.